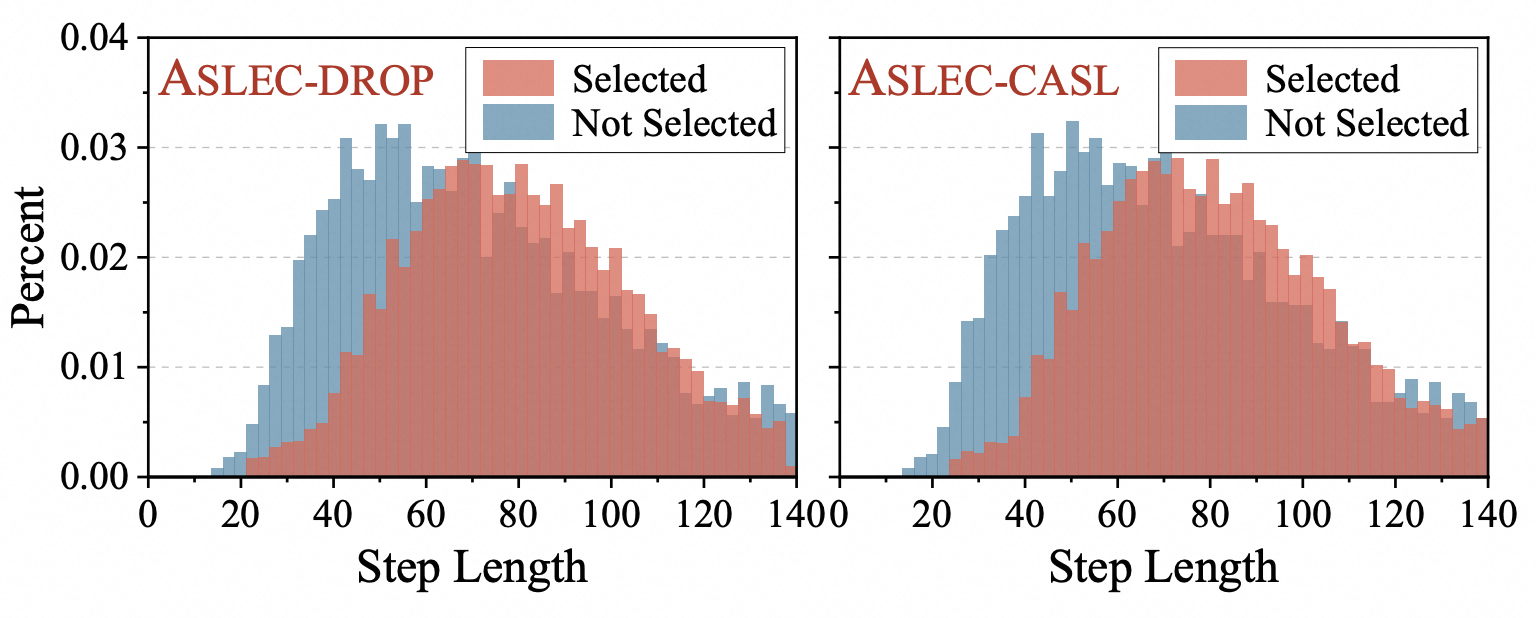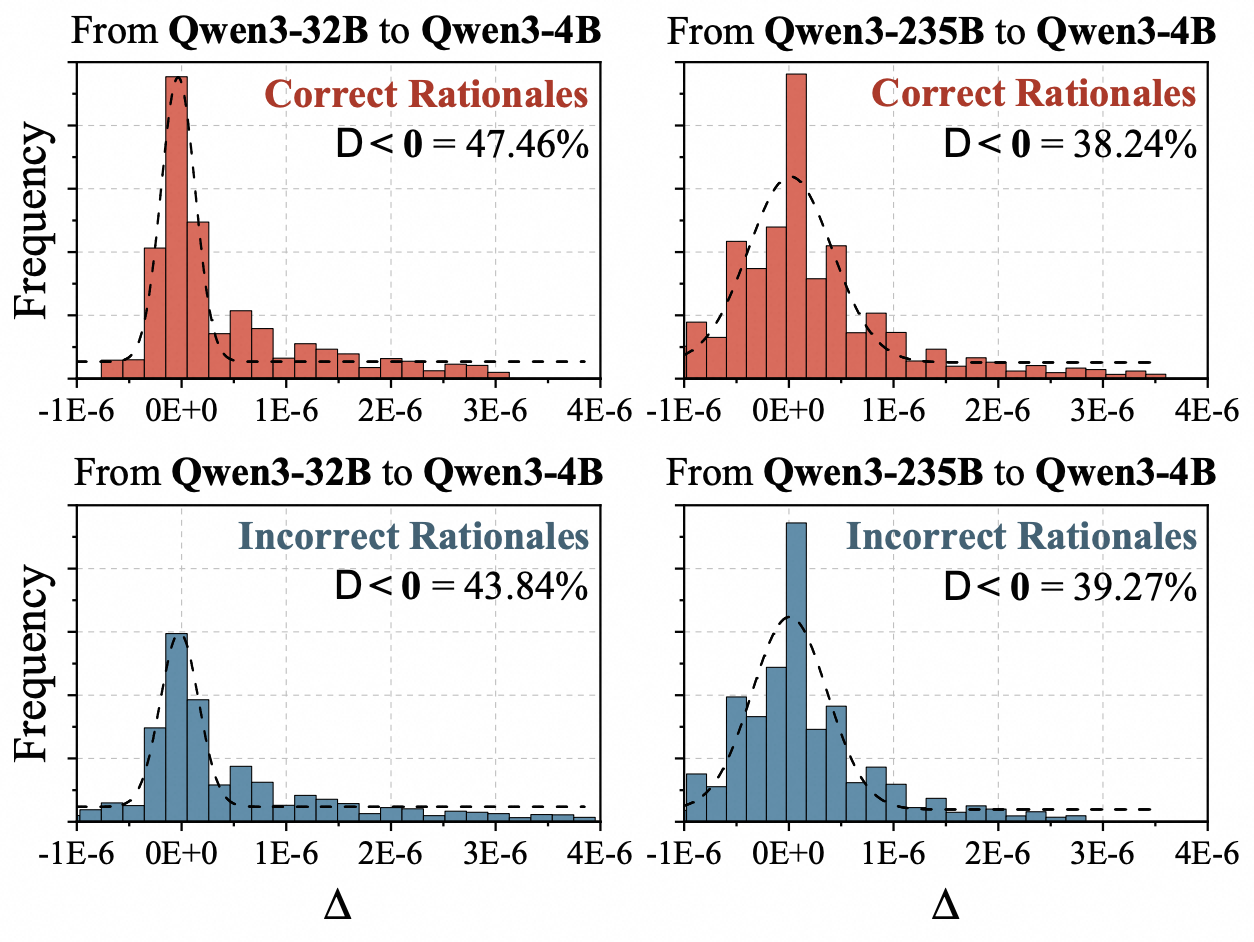
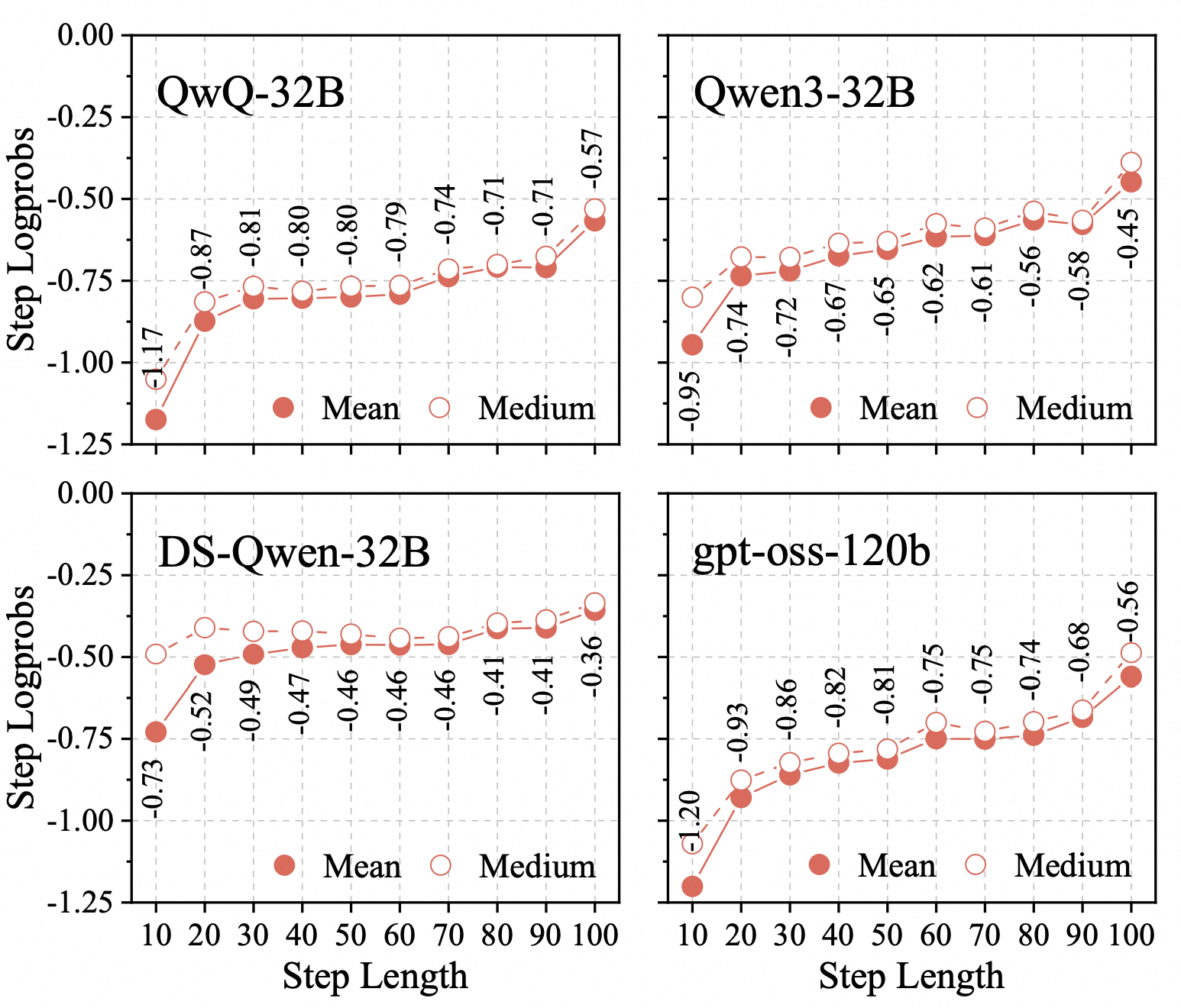
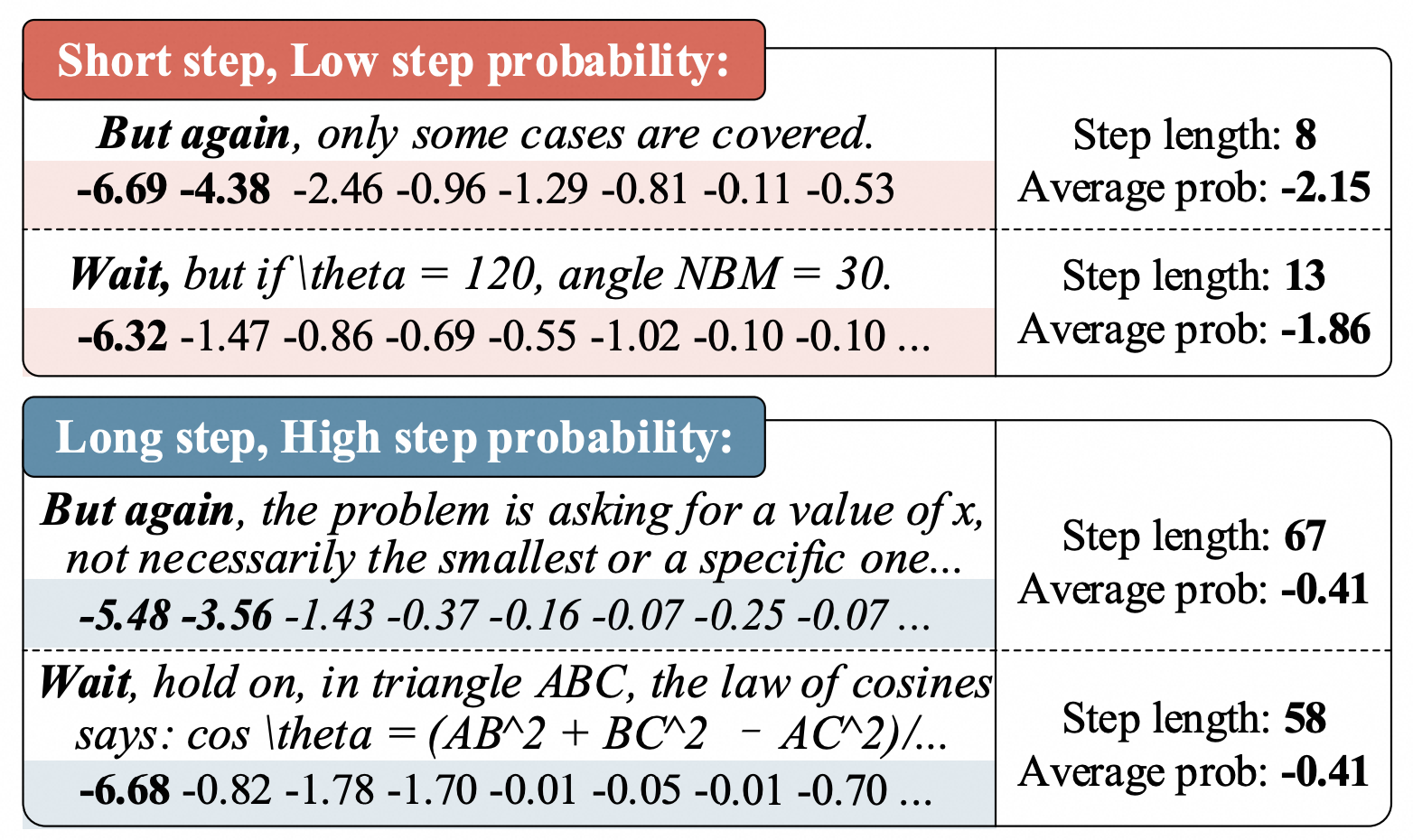
Main Results on LIMO-v2
Select 4k from 16k responses (5 responses per source LLM × 4 LLMs × 800 problems).
| Model | Method | AIME24 | AIME25 | MATH500 | OlympicB | Avg. |
|---|---|---|---|---|---|---|
| 4B-Base | GRACE | 16.66 | 15.83 | 59.40 | 33.33 | 31.42 |
| Local LP | 19.16 | 20.83 | 71.60 | 34.11 | 36.50 | |
| + ASLEC-drop (ours) | 30.00 ↑10.84 | 28.33 ↑7.50 | 77.80 ↑6.20 | 38.38 ↑4.27 | 44.64 | |
| + ASLEC-casl (ours) | 31.66 ↑12.50 | 30.83 ↑10.00 | 80.00 ↑8.40 | 42.81 ↑8.70 | 47.54 | |
| 8B-Base | GRACE | 30.83 | 21.66 | 72.00 | 39.70 | 42.36 |
| Local LP | 34.16 | 20.83 | 76.60 | 42.81 | 44.06 | |
| + ASLEC-drop (ours) | 41.66 ↑10.50 | 36.66 ↑15.83 | 81.40 ↑4.80 | 47.85 ↑5.04 | 52.92 | |
| + ASLEC-casl (ours) | 45.00 ↑13.34 | 37.50 ↑16.67 | 85.40 ↑8.80 | 49.03 ↑6.22 | 56.15 | |
| 4B-Instruct | GRACE | 59.16 | 50.00 | 79.36 | 47.79 | 63.82 |
| Local LP | 61.66 | 49.16 | 80.75 | 50.14 | 65.84 | |
| + ASLEC-drop (ours) | 69.16 ↑7.50 | 56.66 ↑7.50 | 89.88 ↑9.13 | 57.64 ↑7.50 | 72.77 | |
| + ASLEC-casl (ours) | 71.66 ↑10.00 | 58.33 ↑9.17 | 93.20 ↑12.45 | 60.44 ↑10.30 | 76.16 | |
Table 1. Experimental results on LIMO-v2. Red arrows indicate improvement over Local LP (SOTA baseline). Bold: best score.